LLaMA(Large Language Model Meta AI)系列大型語言模型是Meta公司在自然語言處理領域的重要進展,每一代的開發都展示了強大的效能和出色的開源理念,並通過減少Transformer上的一些運算,以實現更快的推理速度,從而解決這些大型語言模型對硬體高度依賴的問題。
而在今天的文章中我們將了解LLaMA系列模型(包括LLaMA 1、LLaMA 2 和 LLaMA 3)的強大之處,而這些技術也是在當前大型語言模型的主流研究,因此我在今天會特別把一些數學式展示出來,讓你迅速掌握這些模型的要點與實際應用。
LLaMA 1是Meta首次進軍大型語言模型領域的重要作品。它的問世打破了OpenAI、微軟和Google對大型語言模型的壟斷,成為開源語言模型的先驅。雖然LLaMA 1的開源僅限於學術研究,但其擁有130億(13B)至650億(65B)個模型參數,讓不少學者能減少訓練資源不足的問題。而13B的模型甚至可以在單塊消費級顯卡(內存24GB的顯卡如:3090、4090、V100等)上使用,而且其效能在大多數基準上能與參數量高達1750億的GPT-3競爭。
而其訓練資料集並不像OpenAI、微軟和Google等企業那樣不公開透明。他使用的技術完全來自我們能自行找到的資料。如果我們的資源足夠,甚至可以完全訓練出自己的LLaMA模型,以下是LLaMA在訓練時使用的公開資料集名稱,若有興趣也可以去看看這些資料的詳細資訊。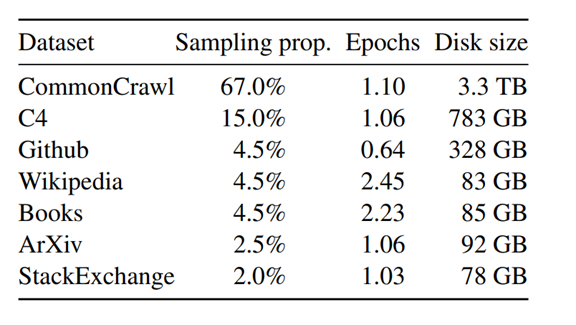
當然LLaMA 1不僅僅是開源在模型設計上也做出了許多優化。首先是RMSNorm歸一化函數,相比於Transformer的LayerNorm,RMSNorm只計算特徵值的均方根,而不計算均值,這使得計算速度更快梯度也更穩定,其數學公式其實與LayerNorm相似,只是移除了均值的計算並改用均方根。
第二個改動是針對激勵函數,在原始的Transformer中通常會使用ReLU或GELU(例如BERT使用GELU),但是ReLU在輸入小於0時會導致梯度消失的問題,而GELU雖然平滑,計算成本卻較高。LLaMA則採用了SwiGLU激勵函數,該函數結合了門控機制和平滑運算,其數學式如下: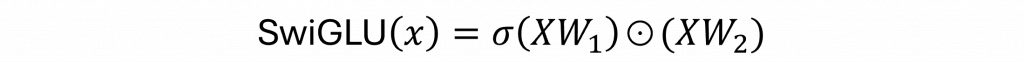
對於每個輸入 X,該激勵函數會首先通過兩個線性變換 W1 和 W2,分別產生兩個不同的輸出。其中在 W1 上會通過 Sigmoid 函數來產生一個在 [0, 1] 範圍內的門控信號,用以控制每一層的訊息流入,並與 XW2 進行逐元素相乘。這提供了一個更平滑且可微的激活函數,使模型訓練更加穩定並提高效能。我們可以看到這些 ReLU 變體的相關曲線圖如下。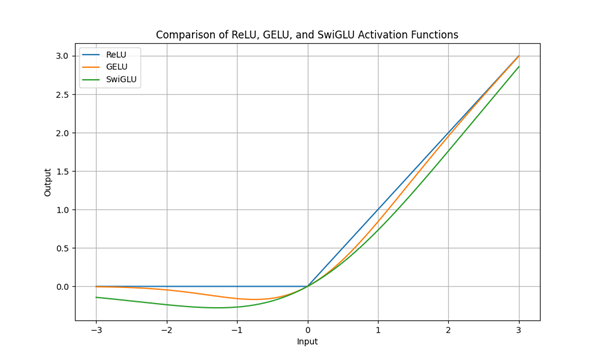
最後一個方法是將 Positional Encoding 改為旋轉位置編碼(Rotary Embeddings, RoPE)。這種方式基於數學中的極座標系統,通過將每個 token 的位置編碼與查詢和鍵向量進行旋轉變換,來實現相對位置編碼。Rotary Embeddings 的核心思想是通過旋轉變換矩陣影響查詢和鍵向量的內積,從而編碼相對位置。這裡的旋轉變換基於複數數學或二維向量旋轉的概念。對於每個維度 d,我們將奇數和偶數維度組成一對進行旋轉變換。因此我們針對Transfromer時其旋轉變換可以寫成: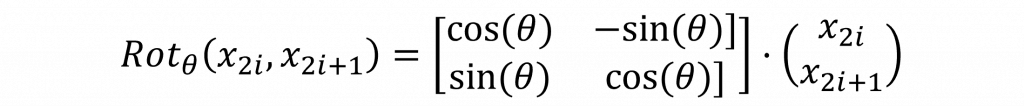
簡單來說這意味著每對奇偶維度會被旋轉一個角度,而這個角度通常是根據 token 的位置信息設置的。通過這種方式,Rotary Embeddings 可以有效地引入位置資訊,並保留相對位置之間的關係,從而提升模型的表現。此外,上述數學公式可以用原始論文中的圖片來表示。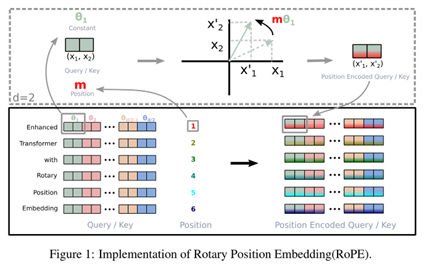
2023年7月Meta推出LLaMA 2,此版本不僅擴大了40%的預訓練數據,還延長了輸入的文本長度,並繼續使用與LLaMA 1類似的架構,但它最大的改進來自於Global Query Attention,這種改進使每個Q可以共享全局Q向量,從而顯著減少了記憶體需求和計算量,使其運算與訓練速度更快。
具體來說多頭注意力機制需要為每個head計算Q、K和V之間的關係,而每個head都需要獨立計算注意力分數並拼接在一起進行線性變換,這導致計算量非常大。LLaMA 2採用了Global Query Attention的架構,讓一組全局共享的Q與所有的K和V進行交互,而不是為每個查詢單獨計算,這大大減少了計算需求並提高了效率。
LLaMA 2 也針對長文本處理(GMS8K)、程式碼編寫(HumanEval)和語意理解(MMLU)等自然語言處理任務進行了優化,使性能提升明顯,而自此版本開始允許商業用途,為企業應用打開了大門。
在2024年4月LLaMA 3問世再次引起轟動。根據公開的測試結果,**LLaMA 3的70B參數模型在性能上與主要競爭對手相當,並且相較於LLaMA 2性能提升了超過20%。**LLaMA 3的優勢在於進一步優化了多頭注意力機制,同時改進了模型的訓練策略,使得相同參數量下的性能得到了大幅度的提升。且Llama 2相比,Llama 3的預訓練資料量從1.8兆增加到15兆,大幅提升了模型訓練資料的規模。
目前公開的LLaMA 3版本包括8B、70B和405B的模型,而LLaMA 3在原始的論文中被稱為「herd of language models」,這是因為其效能旨在與目前最先進的語言模型(如GPT-4)競爭並且能做到多個語言模型才能做到的事情。此外與LLaMA 1和LLaMA 2只能輸入4k與8k個Token不同,這次模型一口氣提升到了128k個Token的輸入,是一個強而有力的進展。
其模型在架構上並未與前代有太大的差異,最大的差異在於它使用了兩個主要訓練階段預訓練和後訓練(Post-Training),並在這兩個任務中加入了許多優化技巧,例如:在預訓練階段是為了適應人類指令並優化特定能力(如程式設計、推理等),而其最主要的任務就是讓模型預測下一個Token。這個訓練過程包括從標準預訓練到進一步的預訓練,以擴展模型的上下文視窗(Context Windows),即Token的輸入數量。而在後訓練階段,模型進行了Instruction learning和DPO(Direct Preference Optimization),使它更加符合人類回饋,並具備特定的功能,如工具使用和推理能力。
而在資料集的方面進行了更嚴謹的資料處理。例如: 在預訓練階段進行了相似文件的去重,且在訓練過程中,不像MAML那樣先用單一類型的資料集分階段訓練或調整**,而是使用了混合資料集來提高模型的泛化能力**。
在後訓練階段,除了採用SFT(Supervised Fine-Tuning)與DPO外,還使用了拒絕採樣(Rejection Sampling)策略,使其能從從大量模型生成的數據中選取最優輸出,並通過PagedAttention提高了採樣效率。
拒絕抽樣是一種從目標分布中產生樣本的蒙地卡羅方法,用於在無法直接從目標分布中抽樣的情況下進行樣本生成。它依賴於一個較易抽樣的
提議分布(Proposal Distribution),並利用拒絕/接受樣本的機制來逼近目標分布。PagedAttention則是一種改進 Transformer 模型中的注意力機制的方法,它旨在減少計算資源的使用,尤其是記憶體佔用。在原始的 Transformer 模型中,隨著輸入序列長度的增加,注意力機制的計算量和記憶體需求會急劇上升,因為每個序列的每個位置都需要與其他所有位置進行計算。而PagedAttention目的是為了應對這一問題,並使其在更長的輸入序列上運行得更加高效。[Paper]
簡單來說LLaMA 3 的強大能力源自於以下幾點:基於更多且更乾淨的資料集、使用更加細膩的 Token 進行訓練、修改了 RoPE 的基頻超參數並增加到 500000[paper],以達到更長的輸入。這些改進使得模型在處理複雜任務時表現更佳。此外,它還採用了與 ChatGPT 中 RLHF 技術去年的文章相似的 DPO 來進行人類優化。
RLHF是一種將
強化學習(Reinforcement Learning,RL)與人類反饋相結合的技術,用於訓練人工智慧系統,特別是在處理複雜、模糊的目標時,這些目標難以透過明確的數學公式來定義或衡量,其方式就是收集人類反饋資訊讓模型知道該回復的好壞,已讓他計算出對應的獎勵來更新模型的相關參數。
DPO則是直接根據人類的偏好來優化模型的行為,而不是依賴間接的獎勵信號,這一技術可以被視為RLHF的一種變體,因為他只會根據人類的偏好來優化模型的行為,避免了強化學習中獎勵設計過於複雜或不直觀的問題。
在整個 LLaMA 系列中,其實是從多篇論文中找尋方法,包括我們先前提到的 GPT-1 到 InstructGPT 以及後續 ChatGPT 的 RLHF 技術。LLaMA 還參考了多項優化記憶體與速度的技術論文,例如 PagedAttention 與 Global Query Attention 架構。這些方法的應用造就了 LLaMA 3 的強大能力。
不過該論文信息量相當大,因此我僅擷取了一些重點來幫助你理解 LLaMA 3 的強大之處,因此今天的內容中我只會擷取前幾天提到的重點,並忽略論文中有關圖像、語音和記憶體空間節省的詳細資訊。如果你有興趣了解更完整的相關知識,可以參閱 LLaMA 3 的原論文。


 iThome鐵人賽
iThome鐵人賽